Mutex operations are generally expensive on modern architectures and impose harsh limits on the concurrent throughput and scalability of an algorithm or system. Nonetheless mutual exclusion is easy to understand, widely applicable and is a prevailing method of solving resource sharing in concurrent systems.
Overview
Mutexes are designed to allow safe access to shared resources in a multi-threaded environment. Before accessing the protected resources a mutex is locked (or acquired) and afterwards the mutex is unlocked (or released). The program section that accesses shared resources under lock is called a critical section. To achieve cross-thread synchronization mutexes employ atomic read-modify-write operations which are coupled with, or implicitly provide, memory fences that ensure visibility of any memory writes that occured prior to a reacquisition of a critical section.
A mutex comes in multiple flavors. Simple locks, like std::mutex, can only be acquired in an exclusive access mode. A recursive lock is a slightly more complex variant that can be safely locked by the same thread multiple times, however to facilitate that the mutex needs a mechanism to keep track of the owning thread.
Of particular interest are some locks that allow more complex access modes, specifically shared access in addition to exclusive ownership. Also called read-write locks and shared mutexes, those locks allow multiple consumers to access the guarded section under shared (read) ownership or up to a single consumer under exclusive (write) ownership.
Some locks that allow shared access also facilitate explicit upgrading of a shared holder to an exclusive holder. This is interesting, for example, when we would like to update a record but locating that record might be an expensive operation (large database, slow storage, etc.), in which case it makes sense to avoid locking the shared resource exclusively until we have found said record. However for this to actually be useful a strong invariant needs to be in place: The lock upgrade is an atomic operation and no other consumers are allowed exclusive access to the shared resource during the lock upgrade. Otherwise any mutations to the shared resource that could have happened after shared lock acquisition but before exclusive acquisition via lock upgrade would invalidate any data that was collected while holding the shared lock (like where our record should be).
This, however, is a recipe for a deadlock: Simultaneously upgrading two shared holders results is an unsatisfiable requirement as up to one of the holders can be granted exclusive access, breaking the invariant we set in place for the other holder. The common approach to address this to create a third access mode: Upgradeable access. Upgradeable holders aren’t mutually-exclusive with shared holders, but are mutually-exclusive with other upgradeable and exclusive holders, this avoids the pitfall while still allowing concurrent access with shared holders.
Formalization
Creating a formal model of our ideas helps by providing us with a clear picture of the design. Weak design choices can be exposed and a formal model can be formally verified and proven to be correct.
Let $Q=\lbrace A,X,U,S \rbrace$ be our set of states and $\mathcal{O}=\lbrace\mathcal{x},\mathcal{s},\mathcal{u},\mathcal{r},\mathcal{up}\rbrace$ our possible operations. A deterministic finite-state machine of possible mutex states for a single consumer and transitions can be seen in the following figure:
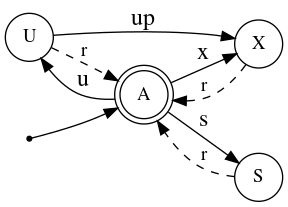
We do not provide lock downgrade facilities as those are of little practical interest. Note that the state-machine in figure 1 represents a single consumer. It becomes more interesting once we have multiple consumer:
Given $n$ consumers, we will construct $M$, our deterministic finite-state machine for our multi-consumer mutex, in a way not dissimilar to powerset construction. Let $\hat{Q}$ be the possible set of states that our mutex can be in, then $\hat{Q}\subseteq Q^n$ where $Q^n$ is the n-ary cartesian power of $Q$, that is $$Q^n=\lbrace\left(s_1,s_2,\cdots,s_n\right)|s_i\in Q\rbrace$$
For example, the state $(A,S,S)\in Q^3$ represents a state with three consumers where consumer 1 hasn’t acquired the mutex, and consumers 2 and 3 have acquired a shared lock.
Given $\hat{s}=(s_1,s_2,\cdots,s_n)\in \hat{Q}$, our invariants are as follows:
- $X$ is a mutually exclusive state: $$\exists i: s_i=X \rightarrow \forall j\ne i: s_j=A$$
- $U$ is mutually exclusive with $X$ and $U$: $$\exists i: s_i=U \rightarrow \forall j\ne i: s_j\in\lbrace A,S \rbrace$$
- Transitions are atomic, meaning a legal transition only modifies the state of a single consumer.
- Legal transitions modify a consumer’s state in accordance to the automaton represented in figure 1.
This gives rise to consolidated states for the automaton $M$:
- Unacquired state = $\hat{A}=\lbrace(A,A,\cdots,A)\rbrace\subset Q^n$
- Shared state - $\hat{S}=\lbrace(s_1,s_2,\cdots,s_n)|\exists i: s_i=S \land \forall j: s_j\in\lbrace A,S\rbrace\rbrace\subset Q^n$
- Exclusive state - $\hat{X}=\lbrace(s_1,s_2,\cdots,s_n)|\exists i: s_i=X, \forall j\ne i: s_j=A\rbrace\subset Q^n$
- Upgradeable state - $\hat{U}=\lbrace(s_1,s_2,\cdots,s_n)|\exists i: s_i=U, \forall j\ne i: s_j=A\rbrace\subset Q^n$
- Shared-upgradeable state - $\hat{SU}=\lbrace(s_1,s_2,\cdots,s_n)|\exists i,j: s_i=U, s_j=S, \forall k\ne i: s_k\in\lbrace A,S\rbrace\rbrace\subset Q^n$
Notice that the states are pairwise disjoint, i.e. $\forall x,y\in\lbrace\hat{A},\hat{S},\hat{X},\hat{U},\hat{US}\rbrace\rightarrow x\cap y=\emptyset$, and that any legal state $\hat{s}=(s_1,s_2,\cdots,s_n)\in Q^n$ must belong to one of those states or else it would violate invariant 1 or 2. Therefore those sets form a partition of $\hat{Q}$, that is $\hat{Q}=\hat{A}\cup\hat{S}\cup\hat{X}\cup\hat{U}\cup\hat{US}$.
Now let’s look at the possible transitions. In accordance to invariant 3 we can define the set of all the operations on $M$ as $\hat{\mathcal{O}}=\mathcal{O}\times \lbrace 1,2,\cdots,n\rbrace$, i.e. pairs of a lock operation coupled with consumer index. However not all such transitions are legal:
- $\hat{s}\in \hat{X}$
- Clearly the only possible transition is release of the exclusive held consumer: $\hat{r}=\lbrace(r,i)\in\hat{\mathcal{O}}|s_i=X\rbrace$.
- $\hat{s}\in \hat{S}$
- Acquisition of a shared holder: $\hat{s}=\lbrace(s,i)\in\hat{\mathcal{O}}|s_i=A\rbrace$.
- Acquisition of an upgradeable holder: $\hat{u}=\lbrace(u,i)\in\hat{\mathcal{O}}|s_i=A\rbrace$.
- Release of a shared holder: $\hat{r}=\lbrace(r,i)\in\hat{\mathcal{O}}|s_i=S\rbrace$.
- $\hat{s}\in \hat{U}$
- Acquisition of a shared holder: $\hat{s}=\lbrace(s,i)\in\hat{\mathcal{O}}|s_i=A\rbrace$.
- Upgrade of the upgradeable holder to an exclusive holder: $\hat{up}=\lbrace(up,i)\in\hat{\mathcal{O}}|s_i=U\rbrace$.
- Release of the upgradeable holder: $\hat{r}=\lbrace(r,i)\in\hat{\mathcal{O}}|s_i=U\rbrace$.
- $\hat{s}\in \hat{SU}$
- Acquisition of a shared holder: $\hat{s}=\lbrace(s,i)\in\hat{\mathcal{O}}|s_i=A\rbrace$.
- Release of a shared holder: $\hat{rs}=\lbrace(r,i)\in\hat{\mathcal{O}}|s_i=S\rbrace$.
- Release of the upgradeable holder: $\hat{ru}=\lbrace(r,i)\in\hat{\mathcal{O}}|s_i=U\rbrace$.
- $\hat{s}\in \hat{A}$
- Acquisition of a shared holder: $\hat{s}=\lbrace(s,i)\in\hat{\mathcal{O}}\rbrace$.
- Acquisition of an upgradeable holder: $\hat{u}=\lbrace(u,i)\in\hat{\mathcal{O}}\rbrace$.
- Acquisition of an exclusive holder: $\hat{x}=\lbrace(x,i)\in\hat{\mathcal{O}}\rbrace$.
The above list partially defines $\delta:\hat{Q}\times\hat{O}\rightarrow\hat{Q}$ which is $M$’s transition function, undefined transitions are illegal. This effectively concludes our construction of $M$:
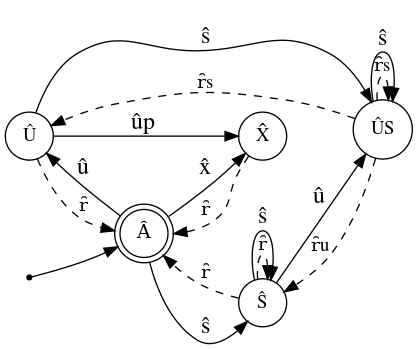
Note: $\delta$ acts on ordered tuples of $\hat{Q}\times\hat{O}$ however figure 2 is a relaxed representation of $M$ where states and transitions are grouped by class, therefore some of $M$'s states have multiple different transitions that correspond to the same operation. Nonetheless, this is a deterministic finite-state machine and those transitions are well defined by the logic outlined above. E.g. $\hat{S}$ with operation $\hat{r}$: $\hat{S}$ transitions to $\hat{A}$ with operation $\hat{r}$ if there is only one shared consumer, otherwise it transitions back to $\hat{S}$. As the operations are atomic, this is well defined.
Design
The model depicted in figure 2 needs to be translated into code. Correctness will be achieved as long as our implementation’s transitions are atomic and follow the model, including forbidding illegal transitions. The rest of the design choices are guided by performance considerations.
Atomic operations under contention are expensive and we generally would like to design our critical sections to be small and avoid heavy contention. Therefore uncontended lock acquisitions are the most common mutex operations, and exclusive is the most typical access mode, so it makes sense to optimize for those scenarios. One of the fastest atomic read-modify-write instructions available on x86 architectures is the bts instruction with lock prefix, which does an atomic bit-test-and-set operation, setting a chosen bit of a variable and returning its previous value. The obvious way to exploit that for lock acquisition is via having dedicated flag bits, e.g. via the following simple structure:
struct mutex_latch {
inline constexpr std::size_t bits = 32;
int acquired_flag : 1;
int upgradeable_flag : 1;
int shared_counter : bits - 2;
};This is the mutex _latch_, it holds the state and is all that is needed to manipulate the mutex:
- The acquired flag is set to 0 when state is $\hat{A}$, otherwise it is set to 1.
- The upgradeable flag is set to 1 when we are in $\hat{U}$ or $\hat{SU}$ state.
- The shared counter keeps count of current count of shared holders. When the counter is $\gt1$ then we are in $\hat{S}$ or $\hat{SU}$ state, depending on the value of the upgradeable flag. It is important not to let the counter overflow.
- When the upgradeable flag and shared counter are null but the acquired flag is set, we are in state $\hat{X}$.
More sophisticated structures can be designed, depending on how many bits of information we are willing to allocate, but this is a very simple one to follow and can be quite performant.
Acquisitions, upgrades and releases are performed as follows:
- Exclusive acquisition is done via an atomic bts on bit 0 which returns 0 only when the acquisition is successful and we have atomically transitioned from $\hat{A}$ to $\hat{X}$. If the return is 1 then the mutex is held by other consumers and we are not allowed to acquire. Release is done simply by an atomic store to the latch that clears all bits to 0.
- Upgradeable and shared acquisitions and releases are done via typical atomic compare-exchange loops. For acquisition the initial compare-exchange is done optimistically by assuming the lock is not held by any consumer. On a failed compare-exchange we examine the current latch value and if our desired state constitutes a legal transition from the current state, we update the expected and desired values and proceed with the loop, otherwise lock acquisition is unsuccessful. Release operations are done in a similar fashion, but observe that releases do not fail.
- Upgrades are done via a compare-exchange loop as well. We hold an upgradeable lock, therefore we are guaranteed that no exclusive holders can acquire the mutex, i.e. the only possible states are $\hat{U}$ and $\hat{SU}$. So, effectively, we need to wait for the lock to be in state $\hat{U}$ to upgrade to $\hat{X}$, as an upgrade is not possible from $\hat{SU}$.
Backoff policy
Once a thread fails to perform a mutex state transition it can either fail the operation or wait for the mutex to arrive at a state that permits said transition. The waiting strategy is called the backoff policy and is crucial in achieving a balanced implementation that attains good performance across a variety of access patterns, contention levels and on different architectures.
Aggressively retrying to re-execute a mutex operation is called busy waiting and would cause a repeated issuing of expensive atomic operations, needless pressure on the caches and, in general, a waste of resources. Instead, a waiting thread has multiple options at its disposal:
- Yield its time slice, i.e. std::this_thread::yield() or equivalent. This is frees up another threads to run, but we need to pay the high cost of a context switch, which on modern systems will easily run up north of 1000ns.
- Spin wait $-$ Loop with one or more x86 pause instructions while waiting. pause blocks the calling thread for a short but unspecified duration. No other threads are rescheduled, however on SMT architectures (the vast majority of modern x86 chips) pause frees up resources to the thread(s) sharing the same physical core. As it is common for critical sections to be released faster than a context switch could be performed, pause is a very useful way to cheaply yield hardware resources.
It is important to note, however, that pause block durations vary greatly between architectures. E.g. Intel has increased the wait time by an order of magnitude (!) on SkylakeX (2017) architectures. Therefore the design should be flexible. - Park $-$ Blocks the thread until woken up. Requires waiting upon an operating system synchronization primitive, generally a condition variable. This is at least as heavy as yielding the thread, but ensures that we have control on when the thread is to be waked up.
A good backoff policy will combine one or more of the options listed above into a strategy consisting of backoff iterations and recheck the mutex latch state between iterations. The initial iterations would be more aggressive and optimistic, attempting to free up hardware resources cheaply and for a short duration before rechecking the latch while later iterations are more pessimistic. In essence this is the well studied exponential backoff algorithm. Immediately yielding the thread’s time slice might sound less wasteful at first, but if we pay >1μs for a needless context switch when the entire critical section might cost 200ns, we have in practice wasted >800ns of CPU time and made the effective resource cost of that critical section over five times higher than it could be.
It is important to avoid actually attempting a transition after a backoff iteration without checking the mutex state first as in all likelihood the mutex is still occupied and an atomic read-modify-write instruction is significantly more expensive than a cache miss due to a memory load with acquire semantics.
Therefore, a backoff policy would start with iterations that issue a few pause instructions, and would quickly raise the count of pauses with each iteration. As long as we have enough work to schedule, i.e. active threads which can progress, we can be pessimistic: A few extra pause instructions are less wasteful than needlessly frequent cache misses as a pause loop consumes precious little resources. Once the spin times reach some threshold we assume the mutex is not going to be available to us in the immediate future and park the thread to let other threads do meaningful work. Unless we have additional information we can use, the outlined exponential backoff policy is a very good general purpose backoff strategy that will, on average, perform well under different conditions.
Breaking symmetry: Assume our mutex is in state $\hat{X}$ (held exclusively) and we have a couple of threads trying to acquire the mutex, also with exclusive access mode. The state queries performed between backoff iterations are likely to result in read cache misses when the mutex is under contention as the latch value might be mutated by another core (due to another thread attempting an initial acquisition, or a thread releasing the mutex, etc.). This means that our waiting threads have to query for latch data, either from the core responsible for the modification (via an interconnect protocol), or to wait for a shared cache to be updated or through a bus operation to fetch the latch value. The process varies and greatly depends on architectural differences (non-inclusive L3 caches on newest AMD and Intel chips might make it more expensive) but generally both waiting threads have to wait for the same, relatively expensive, process causing them to synchronize into lockstep. Lockstepped threads executing atomic operations on the same cacheline interfere with each other, they will both read the same state and will both attempt to transition the lock at the same time. To break the lockstep we would like to inject some randomness into each backoff iteration, e.g. by adding a randomness into the count of pause instructions we use while spinning. The randomness needs to be large enough to offset expensive cache misses.
Parking: If we decide to park a thread it is our responsibility to wake it up (unpark) at the appropriate time, failing to do so results in the a deadlocked thread. The appropriate time to do would be on lock release, e.g. during the release of an exclusive lock we would try to unpark a single parked exclusive waiter, or all parked shared waiters. It makes sense to keep track of parked threads and unpark only if there is a parked waiter. Parking requires the construction of a synchronization primitive as well as a mechanism for other threads to access those primitives to be able to unpark a thread. A parkinglot can be used (see Folly’s or WebKit’s implementations, or the implementation provided at the bottom of this article). A parkinglot statically constructs a global, fixed-sized key-value table shared amongst all consumers and allows us to efficiently park a thread using a key: A unique value generated for each mutex as well as the parked thread access mode, and quickly find relevant threads to unpark.
Other backoff policies: Different backoff policies can be employed when locking the same mutex. For example, at times we might be interested in reducing latency, even at the cost of throughput, on a specific thread (e.g. UI thread). To that end we can employ a more aggressive backoff strategy which reduces the spin counts and never parks (i.e. treat the mutex as a spin-lock) while employing a more conventional backoff policy on the same mutex from a different thread. Or, if we know that contention is likely, we can employ a relaxed backoff policy that reduces spin iterations, or even immediately parks, when a mutex is locked from worker threads. The ability to use different backoff policies on the same lock can be a valuable tool.
Fairness
It is important to note that the mutex described above is not fair: They are no guarantees about how long, on average, would a waiter wait before they successfully acquire the lock. On the contrary, new non-parked waiters will generally win the acquisition race by the time a parked waiter is unparked and scheduled, and strictly from a performance perspective it is indeed better to let a non-parked waiter, if one exists, acquire the lock and to unpark only as last resort.
Also no mechanisms were discussed to combat writer starvation. One easy technique to do so is to park shared/upgradeable waiters immediately if we notice parked exclusive waiters, and for unpark operations to favor parked exclusive waiters over other parked waiters.
However, fairness and starvation very rarely become an actually problem for typical desktop workloads, and aren’t usually as important as performance for a general-purpose lock.
Scaleability
With mixed workloads we would like to achieve good concurrency with multiple consumers being able to hold a shared lock simultaneously, however, as the latch sits on a single cache line, the bottleneck in acquiring and releasing the mutex is the mediocre throughput of contending atomic read-modify-write operations. A variant of our shared, upgradeable mutex that is suitable for workloads with very high shared-to-exclusive ratio can be developed: The common approach is to separate the latch into multiple slots, with each slot on a separate cache line. This allows shared holders to choose a slot at random when acquiring a lock, reducing contention on each cache line. For a purely shared workload scalability would scale linearly with the count of slots. To avoid using more slots than necessary we keep an active slot counter, increase it when we detect enough concurrency and decrease it when non-shared locking occurs. Locking in shared mode is simple:
bool lock_shared(Mutex &m) {
auto count = m.active_slot_count;
auto n = rand() % count;
if (acquire_slot_shared(m, n)) {
if (m.active_slot_count <= n) {
release_slot_shared(m, n);
return false;
}
// Success
if (count < max_slot_count && load_on_slot > threshold)
m.active_slot_count.atomic_compare_exchange(count, count+1);
return true;
}
return false;
}We choose a slot at random and attempt to acquire it as usual. If successful we need to make sure that the slot is still in play and if so we can try to increase active slot count if we detect enough concurrency on our slot.
Exclusive acquisitions are more involved:
bool lock_exclusive(Mutex &m) {
// Acquire main slot
if (!acquire_slot_exclusive(m, 0))
return false;
auto count = m.active_slot_count.exchange(1);
bool success = true;
for (auto s = 1; s < count; ++s) {
if (m.slots[s] != 0) {
success = false;
break;
}
}
if (success)
return true;
// Revert
m.active_slot_count.exchange(count);
release_slot_exclusive(m, 0);
return false;
}We designate slot number 0 as the main slot. First we acquire the main slot under exclusive access mode, if successful we atomically read the active slot counter and reset it to 1. At this point we have a few guarantees:
- No other consumers have acquired or can acquire the main slot in any access mode.
- No shared acquires will mutate the active slot counter until we release the exclusive lock (because we compare-exchange when incrementing).
That is, the only shared consumers that have or will successfully acquire lock are those which have already mutated their chosen slot, which is less than count (our previous active slot count value), and passed the subsequent counter check. Any other potential shared consumer will fail to lock. Therefore we can safely loop over the slots and if we find any slot that is still occupied, we fail and revert. Otherwise we are successful.
For upgradeable acquisitions we lock the main slot in upgradeable mode but we do not need to check the other slots until we actually upgrade.
While this variant scales very well under specific workloads, this higher complexity comes at a price: There is an obvious performance penalty for non-shared lock acquisition and a much higher memory consumption for the latch.
Source code
Source code for an implementation (and a few benchmarks) is publicly available at https://github.com/ssteinberg/shared_futex. This includes a feature-rich mutex API, multiple variants, including variants that employ x86 TSX (Transactional Synchronization Extensions) for hardware lock ellision, and a compact condition variable designed to work with the upgradeable mutex.
