Wait-free algorithms attract vast interest and are an area of intense research, the motivation being that true lock-free algorithms and data structures provide great benefits in terms of performance and scalability over lock-based variants. However designing lock-free systems isn’t a simple matter.
The reader is expected have basic familiarity with hash tables, lock-free concurrency theory and the C++11 atomic library.
1. Overview
Enforcing system invariants is a far more complex task once you ditch the locks. There are multiple caveats to look out for which I will tackle one by one.
But first, let’s define the goal of this endeavor and what the resulting hash-map should look like:
- We should have basic reading capabilities. A method that queries the table for a specific key and returns the value associated with that key, or signals the caller that no such key is mapped.
- And we should have basic writing methods. Insertion of a key-value pair, and deletion of a specific key.
- Automatically resizable as required. During resize the old table must remain accessible and coherent, and the resize must happen in a robust and scalable manner so that multiple threads can participate and assist resizing.
Those interface implementations’ must be lock-free, block-free and be able to complete their tasks in a bounded amount of steps (as a function of the hash-table size) independent of other threads. In other words, wait-free.
Obviously, data-integrity must be preserved at all times, however no guarantees are made about memory ordering. For example, if multiple threads are writing different values for key K to the table simultaneously and a reader thread is querying key K, the query result can be any of the values that the writers insert, or a previous value for K, but nothing else. It is important to understand that the reader can receive an old value even if it began executing after a writer finished. If enforcing happens-after relation is important, it is up to the caller to provide a load-fence, though in practice it is rarely needed.
I use C++11 and the <atomic> library but this theory can, of course, be implemented using any language/platform combination that supports atomic read-modify-write operations, like compare-exchange (CAS) or linked-load/store-conditional. We will ignore explicit memory orders on atomic operations at the beginning and use the default sequentially-consistent ordering, but we will come back to it later when optimizing performance.
2. Memory Reclamation
Memory reclamation is the foremost issue in lock-free structures. Once we remove data from the structure how can we know that no reader is currently accessing this data? Releasing the memory prematurely will lead to an access violation.
There are plenty of concurrent memory reclamation techniques, the reader is encouraged to consult the literature. Some are patented.
If your std::shared_ptr implementation is lock-free, consider using it.
I decided to use a double reference counting scheme, this simple technique is described by Anthony Williams in “C++ Concurrency in Action”, I will provide a handy general implementation.

This works by having a wrapper structure around the reference counted data. We create the structure with external_counter=1 and internal_counter=0. Once a reader requests access, we atomically increase the external reference counter and give shared ownership of ptr to the reader. When the reader is done with the data it releases a reference by atomically increasing the internal reference counter and so signals ownership release.
Once shared ownership is granted the readers have no access to the external (gray) object. When the shared data is to be removed from the data structure we compare-exchange the external structure with a new one, once succeeded there are no more new readers that can grab ownership of the old data, therefore no concurrent accessors to the external_counter. Now we can atomically decrease the internal_counter by external_counter‘s value, at which point the internal_counter is equal to the minus of the number of readers currently holding shared ownership to the data. Once all the readers are done, internal_counter will be equal to zero and we can safely delete ptr.
We can’t just use an external reference counter as readers will have to access the external structure and the external object might change between reader ownership acquire and release. Likewise we can’t use only an internal counter as we can’t dereference and increase the counter in an atomic operation, resulting in a data race.
So, how would the code look like?
template <typename DataType>
class shared_double_reference_guard {
private:
struct data_struct {
std::atomic<int> internal_counter;
DataType object;
template <typename ... Ts>
data(Ts&&... args) : object(std::forward<Ts>(args)...), internal_counter() {}
void release_ref() {
if (internal_counter.fetch_add(1) == -1)
destroy();
}
void destroy() {
delete this;
}
};
struct data_ptr_struct {
int external_counter;
data_struct *ptr;
};
std::atomic<data_ptr_struct> data_ptr;
};data_struct is the internal (black) structure that contains the shared data itself. data_ptr_struct is the external (gray) wrapper.
You can verify that your implementation is capable of performing lock-free atomic operations on double-machine-word primitives with assert(data_ptr.is_lock_free()). We want to be able to seamlessly acquire and release shared ownership in a typical exception safe C++ fashion, RAII.
So let’s create a movable, non-copyable data_guard:
template <typename DataType>
class shared_double_reference_guard {
public:
class data_guard {
friend class shared_double_reference_guard<DataType>;
private:
data_struct *ptr;
public:
data_guard(data_struct *ptr) : ptr(ptr) { }
data_guard(const data_guard &d) = delete;
data_guard &operator=(const data_guard &d) = delete;
data_guard(data_guard &&d) {
ptr = d.ptr;
d.ptr = nullptr;
}
data_guard &operator=(data_guard &&d) {
if (ptr) ptr->release_ref();
ptr = d.ptr;
d.ptr = nullptr;
return *this;
}
~data_guard() { if (ptr) ptr->release_ref(); }
bool is_valid() const { return !!ptr; }
DataType* operator->() { return &ptr->object; }
DataType& operator*() { return ptr->object; }
const DataType* operator->() const { return &ptr->object; }
const DataType& operator*() const { return ptr->object; }
};
};As long as the data_guard is alive, the underlying data can be safely accessed via the overloaded operators. Once its destructor is called, release_ref will be called and the shared ownership released.
Now lets handle shared_double_reference_guard<T>‘s implementation. We want to be able to acquire ownership, emplace new data and just drop existing data:
template <typename DataType>
class shared_double_reference_guard {
private:
void release(data_ptr_struct &old_data_ptr) {
if (!old_data_ptr.ptr)
return;
auto external = old_data_ptr.external_counter;
if (old_data_ptr.ptr->internal_counter.fetch_sub(external) == external - 1)
old_data_ptr.ptr->destroy();
else
old_data_ptr.ptr->release_ref();
}
public:
shared_double_reference_guard() {
new_data_ptr{ , nullptr };
data_ptr.store(new_data_ptr);
}
~shared_double_reference_guard() {
data_ptr_struct old_data_ptr = data_ptr.load();
release(old_data_ptr);
}
data_guard acquire() {
data_ptr_struct new_data_ptr;
data_ptr_struct old_data_ptr = data_ptr.load();
do {
new_data_ptr = old_data_ptr;
++new_data_ptr.external_counter;
} while (!data_ptr.compare_exchange_weak(old_data_ptr, new_data_ptr));
return data_guard(new_data_ptr.ptr);
}
template <typename ... Ts>
void emplace(Ts&&... args) {
data_struct *new_data = new data_struct(std::forward<Ts>(args)...);
data_ptr_struct new_data_ptr{ 1, new_data };
data_ptr_struct old_data_ptr = data_ptr.load();
while (!data_ptr.compare_exchange_weak(old_data_ptr, new_data_ptr));
release(old_data_ptr);
}
template <typename ... Ts>
bool try_emplace(data_guard &old_data, Ts&&... args) {
data_struct *new_data = new data_struct(std::forward<Ts>(args)...);
data_ptr_struct new_data_ptr{ 1, new_data };
data_ptr_struct old_data_ptr = data_ptr.load();
bool success = false;
while (old_data_ptr.ptr == old_data.ptr && !(success = data_ptr.compare_exchange_weak(old_data_ptr, new_data_ptr)));
if (success)
release(old_data_ptr);
else
delete new_data;
return success;
}
void drop() {
data_ptr_struct new_data_ptr{ , nullptr };
data_ptr_struct old_data_ptr = data_ptr.load();
while (!data_ptr.compare_exchange_weak(old_data_ptr, new_data_ptr));
release(old_data_ptr);
}
};acquire does just that, it atomically tries to increase the external reference and ensures that the reference increased corresponds to the ptr grabbed. Once succeeded an ownership has been acquired and it returns a data_guard.
drop atomically constructs an empty data wrapper and releases the old data.
emplace and try_emplace drop the old data and replace it with new data constructed in-place. try_emplace makes sure that we are actually replacing what we expect and that no one got here before us, to do this we pass an existing data_guard and compare-exchange against it.
So, that is all we need to protect shared data. We will come back to this when optimizing.
3. The Hash Table Algorithm
Now that we have a safe concurrent way to handle memory reclamation let’s design the hash-table itself.
Let’s start with hash resolution. Cache awareness is an absolute must for performant implementations on modern architectures, however most cache-aware resolution techniques require relocating inserted key-value pairs (e.g. Robin-Hood, Hopscotch, pretty much any open-addressed hash table), which is hard to synchronize and requires more expensive atomic read-modify-write operations.
I decided on a simple approach of linearly-probed chained virtual-buckets. Each virtual bucket is aligned on cache line boundary, is the size of a single cache line, contains as many buckets as possible to fit and a single pointer to the next chained virtual bucket. Each such chain of virtual buckets corresponds to a single hash value:

To help find buckets we will store the hash value alongside a pointer to the hash data:
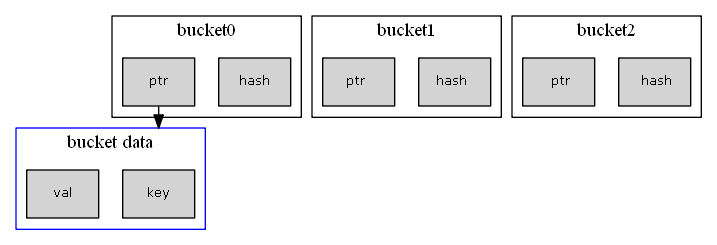
Each bucket contains two machine words, so we can atomically compare-exchange it, however we have a problem, how can we safely dereference and relcaim the pointer? We could, of course, use the memory reclamation technique we discussed earlier but that would mean a bucket would consist of three machine words, and we can’t work with that. Moving the hash value into the data structure would greatly impact the search performance. And anyway each and every update to an external reference counter (every probe!) would invalidate the whole cache line (this is called “false sharing”) violating our cache-aware design guidelines.
A better option is to force immutability of the bucket data: That is, once set by an insert, the hash and pointer don’t change. This way we don’t have to worry about reclaiming. Likewise, the bucket key is immutable, so we only need to worry about the value, and that is fine.
static constexpr int N = cache_line / bucket_size - 1;
struct map_bucket_data {
using value_type = shared_double_reference_guard<mapped_type>;
key_type k;
value_type v;
template <typename S, typename ... Ts>
map_bucket_data(S&& k, Ts&&... args) : k(std::forward<S>(k)), v(std::forward<Ts>(args)...) {}
};
struct map_bucket_ptr {
unsigned hash;
map_bucket_data *data;
};
struct map_virtual_bucket {
std::array<std::atomic<map_bucket_ptr>, N> buckets{ map_bucket_ptr{, nullptr} };
std::atomic<map_virtual_bucket*> next{ nullptr };
void *_unused;
~map_virtual_bucket() {
auto ptr = next.load();
if (ptr)
delete ptr;
for (auto &bucket : buckets) {
auto bucket_ptr = bucket.load();
if (bucket_ptr.data) delete bucket_ptr.data;
}
}
};Each bucket is constructed with hash=0 and data=nullptr, an insert operation _compare-exchange_s the bucket with a new initialized bucket_ptr, if successful that bucket will forever remain mapped to that particular key. So how do we delete? We can drop the value of that bucket and by doing so mark it as a tombstone. Insertions to an existing key, be that a tombstone or not, are done by emplace-ing the new value. Readers need to respect tombstones by acquire-ing the value and checking the data_guard‘s validity, the data_guard can be returned to the caller safely and without even doing a data copy. All those operations on a shared_double_reference_guard are atomic and safe by design.
Finally, we need to prune tombstones at some point. This is easy: We do so when resizing.
4. Resizing the Hash-Table
We can decide to resize once the load factor reaches a certain value, and/or if we have an overfull virtual bucket. The new table size depends on the hash function, I use a power-of-2 table as a bitwise-and is an order of magnitude faster than modulus operation, also linear probing in our case is very fast so I am fine with the increased collision rate due to lower hash entropy.
While readers might participate in the resize process, I decided against it to keep reads as fast as possible. Each writer thread which decides to resize the table, or which detects that a resize is in process, completes its modification on the old table first. That is not strictly necessary, but I’d like to have new data visible as soon as possible. After writing to the old table the writer thread joins (or initiates) the resize.
Once resizing has been initiated a new hash-table needs to be allocated. Multiple threads might create a new table but only one will win the compare-exchange race, the others will dispose of the new tables. Threads that join after a table was created simply use the new table. At this point each writer performs its modification on the new table and then starts to copy and rehash key-value pairs from the old table to the new one. When copying we ignore tombstones and we do not update values, that is we copy only if the key wasn’t found in the new table.
struct hash_table_struct {
unsigned size;
map_virtual_bucket *virtual_buckets;
shared_double_reference_guard<resize_data_struct*> resize;
};
struct resize_data_struct {
unsigned size;
map_virtual_bucket *virtual_buckets;
std::vector<std::atomic<int>> markers;
};shared_double_reference_guard<hash_table_struct> hash_table;
To keep the old table safely alive as long as needed we again use a shared_double_reference_guard<hash_table_struct>, this contains the virtual buckets and the resize structure. Once done with the resize we try_emplace the new resized hash table, again only one thread will win this race, and that thread can also drop the resize object from the old table. At this point readers and writers will transition to the new table.
Now we only need to coordinate the workload distribution between the different threads that participate in the resize. I simply divide the virtual buckets into chunks of 8. Each chunk has a marker that describes the its state:
0 – no work started, 1 – work in progress, 2 – work complete.
Each writer thread that has acquire-ed a valid resize data and completed writing its own modification to the new table can now scan the markers and find an unworked chunk:
for (int i = ; i < chunks; ++i) {
int old_val = 0;
if (!resize_guard->markers[i].compare_exchange_strong(old_val, 1))
continue;
// Ownership of this chunk acquired
// Copy data from all virtual buckets in this chunk
// And mark this chunk as complete
resize_guard->markers[i].store(2);
}Once all chunks are marked as done the copy is finished.
5. Memory Orders
Let’s review the required memory orderings and see what we can relax.
For the readers: The bucket load, value acquire and virtual bucket next pointer load can all be memory_order_relaxed. Writers emplace-ing or drop-ing a bucket value can use a memory_order_release memory ordering semantics to enforce happens-before relation with the resizers reading from the old table with memory_order_acquire semantics.
Moving on to shared_double_reference_guard<>. All the compare_exchange_weak loops can have relaxed ordering semantics on the failure case and on the load of the old data before the loop.
6. Additional optimizations
Lock-free systems are inherently complex and optimizing should be done carefully and only if required. Those optimizations have little to do with lock-free data structures and can reduce portability. This is provided as an example of what can be done as the performance benefit is significant.
Reusing Memory
Firing up the profiler reveals that a lot of time is spent on heap allocation and deallocation. shared_double_reference_guard<DataType> uses a pointer to the external structure that must be dynamically allocated. However, for a move-assignable DataType (bucket values) those pointers can be reused.
We create a thread local storage that keeps a few of those pointers around instead of deleting them, and when a new pointer is required we grab one from that storage and move the data.
template <typename T, int N = 3>
class pointer_recycler {
private:
std::array<T*, N> pointers;
int size;
static_assert(std::is_default_constructible<T>::value, "T must be default-constructible");
static_assert(std::is_move_assignable<T>::value, "T must be move-assignable");
public:
~pointer_recycler() {
for (int i = ; i < size; ++i) {
if (pointers[i])
delete pointers[i];
}
}
void release(T *ptr) {
if (size == N) {
delete ptr;
return;
}
*ptr = T();
pointers[size++] = ptr;
}
template <typename ... Ts>
T* claim(Ts&&... args) {
if (size) {
T* ptr = pointers[--size];
*ptr = T(std::forward<Ts>(args)...);
return ptr;
}
return new T(std::forward<Ts>(args)...);
}
};As a thread local static structure, this simple class can hold and recycle pointers for each thread without needing to free them. This is useful only if the mapped type can be cheaply constructed and move-assigned.
Vectorizing
If we pack the hashes together in the virtual bucket, i.e. keep an array of hashes first, and then an array of pointers (or vice versa), the hashes can vectorized for faster search. It means we need to be more careful when inserting as we no longer can insert the hash and a data pointer in a single atomic operation. That’s fine because we can grab ownership of the hash with a compare-exchange, if no one beats us to it we can store the data. In between, the bucket is still marked as unused because the data pointer is null, however no one else can claim it because the hash is no longer 0. To make it work we need to mark 0 as unused hash and modify the has function to never return 0.
Now we can use SSE or AVX to locate a hash in a few instructions. For example, when compiling 32-bit code 7 buckets fit in a single 64-byte cache line and all those 7 hash values fit in a single 256-bit AVX2 register.
7. Performance and Final Words
Comparing the implementation against Intel TBB’s lock-based hash map (version 16) on a 5th generation i5 running 2 threads with mixed workloads:
- Reader heavy workloads: TBB’s hash map is faster by ~200%.
- Mixed workload: TBB’s hash map is faster by ~75%
- Writer heavy workloads: TBB’s hash map is slower by ~25%.
As expected given the low concurrency and the atomic overhead.
This article is meant to provide an insight into the design process of a lock-free data structure. By no means is it intended to be the best or fastest implementation, although the performance seems to be as good as can be realistically expected.
A primary contention point is the double-reference counted table root pointer and the extra indirection overhead caused by it. If the dynamic resize facilities aren’t required (we can guess the expected size up front) then we can save that indirection, significantly improving performance.
